my jobs
login
Register
Welcome back
- Remember me Forgot password?
- Home
- Analysis Platform

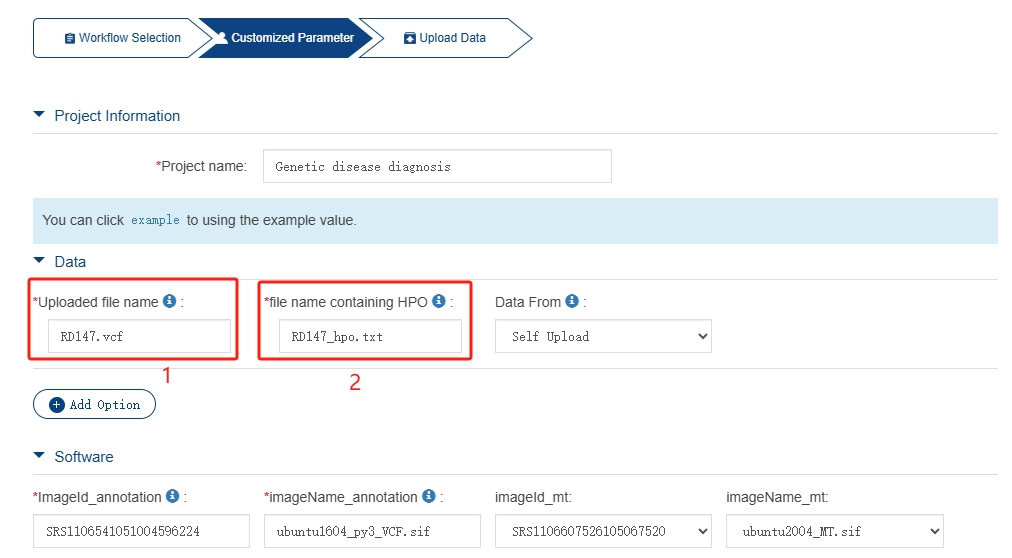
Cancer Genomic Analysis

Precise medication guidance

Transcriptome Expression Data Analysis

RNA-seq Pipeline Accuracy Test

Single Cell RNA-seq Analysis

DNA Methylation Sequencing Data Analysis

WGBS Pipeline Accuracy Evaluation

Proteomics analysis platform

RNA-protein binding sites prediction
- Code Repository
- Software Repository
- Data Repository
- Help
- About Us
- News












 Address: 800 Dong Chuan RD. Minhang District, Shanghai, China SJTU-Yale Joint Center for Biostatistics, SJTU
Address: 800 Dong Chuan RD. Minhang District, Shanghai, China SJTU-Yale Joint Center for Biostatistics, SJTU